[Chapter 2] DNA, RNA, and Protein(보류)
THE CENTRAL DOGMA OF MOLECULAR BIOLOGY
Two essential features of living creatures are the ability to reproduce their own genome and manufacture their own energy. To accomplish these feats, an organism must be able to make proteins using information encoded in its DNA. Proteins are essential for cellular architecture, giving the cell a particular shape and structure. Proteins include enzymes that catalyze reactions used to make energy. Proteins control cellular processes like replication. Proteins provide channels in the membrane for cells to communicate with each other or share metabolites. Making proteins is a key operation for all living organisms. The central dogma of molecular biology states that information flows from DNA to RNA to protein (Fig. 2.1).

FIGURE 2.1 The Central Dogma Cells store genetic information as DNA, which is able to replicate so that daughter cells have the same information as the parent. When a protein is needed, DNA is transcribed into RNA, which in turn is translated into a protein. RNA also functions in a cell to regulate gene expression and as ribozymes that carry out catalytic reactions.
First, this chapter focuses on how RNA is made from DNA in a process called transcription. Next, the mechanisms used to control transcription are discussed. We then discuss how particular RNA molecules called mRNA or messenger RNA are used to make protein in a process called translation. By examining these processes, the reader will gain an understanding of the complexity involved in engineering cells for the purposes of biotechnology.
The central dogma of molecular biology is that DNA is transcribed into RNA, which in turn is translated into proteins.
TRANSCRIPTION EXPRESSES GENES
Gene expression involves making an RNA copy of the DNA code, a process called transcription. Making RNA involves uncoiling the DNA, melting the strands at the start of the gene and moving any histones out of the way, making an RNA molecule that is complementary in sequence to the template strand of the DNA with an enzyme called RNA polymerase, and stopping at the end of the gene.
The newly made RNA releases from the DNA, which then returns to its supercoiled form. Two long-standing questions in biology are how a cell turns genes on and off, and what genes are transcribed at what time in development or function. These questions have multiple answers that are based on the different types of genes. Housekeeping genes encode proteins that are used continually. Inducible genes are converted to protein only under certain circumstances.
For instance, in Escherichia coli, genes that encode proteins involved with the utilization of lactose are expressed only when lactose is present (see later discussion). The same principle applies to the genes for using other nutrients. Various inducers and accessory proteins control whether or not these genes are expressed or made into RNA; they will be discussed in more detail in upcoming sections.
The final product encoded by a gene is often a protein but may be RNA also. Genes that encode proteins are transcribed to give messenger RNA (mRNA), which is then translated to give the protein.
Other RNA molecules, such as tRNA, rRNA, snRNA, and other regulatory noncoding RNAs, are used directly (i.e., they are not translated to make proteins). Some RNA molecules, called ribozymes, catalyze enzymatic reactions. One well-researched ribozyme is an rRNA found in the large subunit of the ribosome (see Chapter 5). The genes that ultimately code for a protein via an mRNA intermediate are studied most often since they are historically thought to be the most important to the function of the organism.
Coding regions of a gene, sometimes called a cistron or a structural gene, have the code to make a protein or a nontranslated RNA. (The term cistron was originally defined by genetic complementation using the cis/trans test.) In contrast, an open reading frame (ORF) is a stretch of DNA (or the corresponding RNA) that encodes a protein and therefore is not interrupted by any stop codons for protein translation (see later discussion).
During transcription, the enzymes that make RNA must identify the start site among the DNA code. Every gene has a region upstream of the coding sequence called a promoter (Fig. 2.2). RNA polymerase recognizes this region and starts transcription here. Bacterial promoters have two major recognition sites: the −10 and −35 regions. The numbers refer to their approximate location upstream or before the transcriptional start site. (By convention, positive numbers refer to nucleotides downstream, or after the transcription start site; and negative numbers refer to those upstream, or before.)
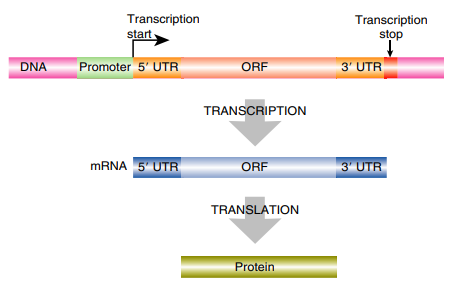
FIGURE 2.2 The Structure of a Typical Gene Genes are regions of DNA that are transcribed to give RNA. RNA can be translated into protein or used directly. The gene has a promoter region plus transcriptional start and stop points that flank the region that is converted into mRNA. After transcription, the mRNA has a 5′ untranslated region (5′ UTR) and 3′ untranslated region (3′ UTR), which are not translated; only the ORF is translated into protein.
The exact sequences at −10 and −35 vary, but the consensus sequences are TATAA and TTGACA, respectively. When a gene is transcribed continually or constitutively, then the promoter sequence closely matches the consensus sequence. If the gene is expressed only under special conditions, activator proteins or transcription factors are needed to bind to the promoter region before RNA polymerase will recognize it. Such promoters rarely look like the consensus. The transcription start site begins after the promoter and denotes where RNA polymerase starts adding nucleotides complementary to the template strand. Between the transcription start site and the ORF is a region called the 5′ untranslated region (5′ UTR). This region is not made into protein but contains translation regulatory elements like the ribosome binding site. Next is the ORF, where no translational stop codons are found. Then there is another untranslated region after the ORF, known as the 3′ untranslated region (3′ UTR).
This region is not made into protein either, and often contains important regulatory elements that modulate the rate of translation. Finally, transcription stops at the termination sequence. Bacterial RNA polymerase is made of different protein subunits. The sigma subunit recognizes the −10 and −35 regions, and the core enzyme catalyzes RNA. RNA polymerase synthesizes nucleotide additions only in a 5′ to 3′ direction. The core enzyme has five protein subunits: a dimer of two α proteins, a β protein, a related β′ subunit, and an ω subunit. The β and β′ subunits form the catalytic site, and the α subunit helps recognize the promoter. The 3D structure of RNA polymerase shows a deep groove that can hold the template DNA and a minor groove to hold the growing RNA.
Genes have a transcriptional promoter, where RNA polymerase attaches to the DNA and begins making an RNA copy of the template strand. The RNA has three regions: the 5′ UTR contains information important for making the protein, the ORF has the actual coding region translated into amino acids during translation, and the 3′ UTR contains other important regulatory elements.
MAKING RNA
In bacteria, once the sigma subunit of RNA polymerase recognizes the −10 and −35 regions, the core enzyme forms a transcription bubble where the two DNA strands are separated from each other (Fig. 2.3). The strand used by RNA polymerase is called the template strand (aka noncoding or antisense) and is complementary to the resulting mRNA. The core enzyme adds RNA nucleotides in the 5′ to 3′ direction, based on the sequence of the template strand of DNA. The newly made RNA anneals to the template strand of the DNA via hydrogen bonds between base pairs. The opposite strand of DNA is called the coding strand (aka nontemplate or sense strand). Because this is complementary to the template strand, its sequence is identical to the RNA (except for the replacement of thymine with uracil in RNA). RNA synthesis normally starts at a purine (normally an A) in the DNA that is flanked by two pyrimidines. The most typical start sequence is CAT, but sometimes the A is replaced with a G. The rate of elongation is about 40 nucleotides per second, which is much slower than replication (∼1000 bp/sec). RNA polymerase unwinds the DNA and creates positive supercoils as it travels down the DNA strand. Behind RNA polymerase, the DNA is partially unwound and has surplus negative supercoils. DNA gyrase and topoisomerase I either insert or remove negative supercoils, respectively, returning the DNA back to its normal level of supercoiling (see Chapter 4).
RNA polymerase makes a copy of the gene using the noncoding or template strand of DNA. RNA has uracils instead of thymines.
TRANSCRIPTION STOP SIGNALS
Bacterial and eukaryotic chromosomes are organized very differently. In prokaryotes, the distance between genes is much smaller, and genes associated with one metabolic pathway are often found next to each other. For example, the lactose operon contains several clustered genes for lactose metabolism. Operons are clusters of genes that share the same promoter and are transcribed as a single large mRNA that contains multiple structural genes or cistrons. Thus, the mRNA transcripts are called polycistronic mRNA (Fig. 2.4). The multiple cistrons are translated individually to give separate proteins. In eukaryotes, genes are often separated by large stretches of DNA that do not encode any protein. In eukaryotes, each mRNA has only one cistron and is therefore called monocistronic mRNA. If a polycistronic transcript is expressed in eukaryotes, the ribosome translates only the first cistron, and the other encoded proteins are not made.
Bacterial mRNA transcripts have multiple open reading frames for proteins in the same metabolic pathway. Eukaryotes tend to have only one open reading frame in a single mRNA transcript.
THE NUMBER OF GENES ON AN mRNA VARIES
Bacterial and eukaryotic chromosomes are organized very differently. In prokaryotes, the distance between genes is much smaller, and genes associated with one metabolic pathway are often found next to each other. For example, the lactose operon contains several clustered genes for lactose metabolism. Operons are clusters of genes that share the same promoter and are transcribed as a single large mRNA that contains multiple structural genes or cistrons. Thus, the mRNA transcripts are called polycistronic mRNA (Fig. 2.4). The multiple cistrons are translated individually to give separate proteins. In eukaryotes, genes are often separated by large stretches of DNA that do not encode any protein. In eukaryotes, each mRNA has only one cistron and is therefore called monocistronic mRNA. If a polycistronic transcript is expressed in eukaryotes, the ribosome translates only the first cistron, and the other encoded proteins are not made.