INTRODUCTION
Replication copies the entire set of genomic DNA so that the cell can divide in two. During replication, the entire genome must be uncoiled and copied exactly. This elegant process occurs extremely fast in E. coli, where DNA polymerase copies about 1000 nucleotides per second.
Although the process is slower in eukaryotes, DNA polymerase still copies 50 nucleotides per second. Many biotechnology applications use the principles and ideas behind replication; therefore, this chapter first introduces the basics of DNA replication as it occurs in the cell. We then review some of the most widely used techniques in genetic engineering and biotechnology, including chemical synthesis of DNA, polymerase chain reaction, and DNA sequencing.
REPLICATION OF DNA
To maintain the integrity of an organism, the entire genome must be replicated identi cally. Even for plasmids, viruses, or transposons, replication is critical for their survival. The complementary two-stranded structure of DNA is the key to understanding its duplication during cell division. The double-stranded helix unwinds, and the hydrogen bonds holding the bases together melt apart to form two single strands. This Y-shaped region of DNA is the replication fork (Fig. 4.1).
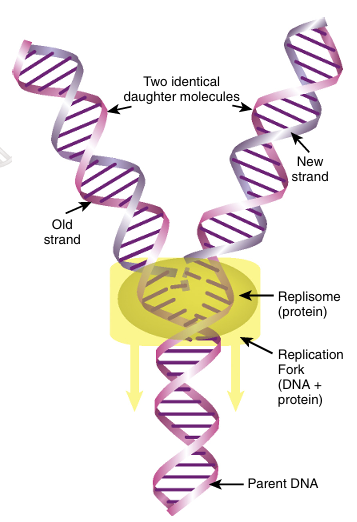
FIGURE 4.1 Replication
Replication enzymes open the double-helix around the origin to make it single-stranded. DNA poly merase adds complementary nucleotides.
Replication starts at a specific site called an origin of replication (ori) on the chromosome. The origin is called oriC on the E. coli chromosome and covers about 245 base pairs of DNA. The origin has mostly AT base pairs, which require less energy to break than GC base pairs.
Once the replication fork is established, a large assembly of enzymes and factors called a replisome assembles to synthesize the complementary strands of DNA (Fig. 4.2).
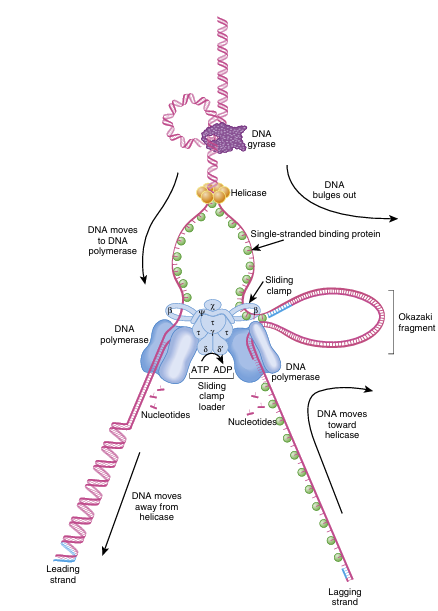
FIGURE 4.2 DNA Polymerase III Replication Assembly
During replication, the sliding clamp loader complex makes contacts with single stranded binding protein and the sliding clamps. This complex stabilizes the two single-stranded DNA strands and provides a stable binding site for two DNA polymerase III molecules.
The unwound single-stranded DNA templates move toward the clamp loader complex. On the leading strand (left), the strand is unwinding in a 3′ to 5′ direction, so DNA polymerase can add complementary nucleotides in the 5′ to 3′ direction. On the lagging strand (right), the template strand is antiparal lel, and therefore, the strand is unwinding in a 5′ to 3′ direction. Since DNA poly merase III must synthesize the new strand in a 5′ to 3′ direction also, the template strand must move toward the helicase. This causes the lagging strand to bubble out from the complex. Once DNA polymerase III reaches the end of the previous Okazaki fragment, the replicated DNA is released by the clamp loader and a new section of single-stranded DNA is reloaded.
The replisome starts synthesizing the complementary strand on one side of the fork by adding complementary bases in a 5′ to 3′ direction. The leading strand is synthesized continuously because there is always a free 3′-OH group. Because DNA polymerase synthesizes only in a 5′ to 3′ direction, the other strand, called the lagging strand, is syn thesized as small fragments called Okazaki fragments. As DNA polymerase makes this strand, the clamp loader must continually release and reattach at a new location. This results in the single stranded region bubbling out from the replisome. The lagging strand fragments are ligated together by an enzyme called DNA ligase. Ligase links the 3′-OH and the 5′-PO4 of neighboring nucle otides, forming a phosphodiester bond. The final step is to add methyl (-CH3) groups along the new strand (Fig. 4.3). The original double-stranded helix is now two identical double-stranded helices, each containing one strand from the original molecule and one new strand. This is why the process is called semiconservative replication.
In replication, DNA polymerase synthesizes the leading strand as one continuous piece and the lagging strand as Okazaki fragments. Each copy has one strand from the original helix and one new strand.
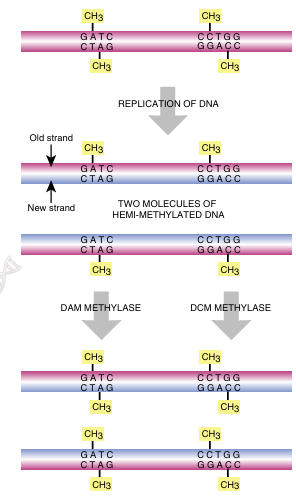
FIGURE 4.3 Hemimethylated DNA: Old Strands versus New
When DNA is replicated, the old strand is methylated, but there is a delay in methylat ing the new strand, and thus, the DNA double helix is hemimethylated. Dam meth ylase and dcm methylase add the methyl groups onto the newly synthesized DNA.
Uncoiling the DNA
Because DNA is condensed into supercoils in order to fit inside the cell, several different enzymes are needed to open and relax the DNA before replication can start (Fig. 4.2).
DNA helicase and DNA gyrase attach near the replication fork and untwist the strands of DNA. DNA gyrase removes the supercoiling, and helicase unwinds the double helix by dissolving the hydrogen bonds between the paired bases.

DNA 슈퍼코일 (super coil) 또는 초나선(superhelix)은 뒤틀린(뒤틈 twist - 2차 꼬임) 이중 나선 디엔에이
(DNA)가 다시 한번 더 스스로를 비틀어(비틈 writhe - 3차 꼬임) 감싸 형성한 둥근 코일 모양을 가리킨다.
The two strands are kept apart by single-stranded binding protein, which coats the single-stranded regions. This prevents the two strands from reannealing so that other enzymes can gain access to the origin and begin replication. As DNA polymerase travels along the DNA, more positive supercoils are added ahead of the replication fork. Because the bacterial chromosome is negatively supercoiled, initially the new positive supercoils relax the DNA. After about 5% of the genome has been replicated, though, the positive supercoils begin to accumulate and need to be removed.
DNA gyrase cancels the positive supercoils by adding negative supercoils. When circular chromosomes are replicated, the two daughter copies may become catenated, or connected like two links of a chain (Fig. 4.4). Topoisomerase IV releases catenated daughter strands by introducing double-stranded nicks into one chromosome. The second copy can then pass through the f irst, giving two separated molecules.
DNA helicase, DNA gyrase, and topoisomerase IV untwist and untangle the supercoiled DNA during replication.
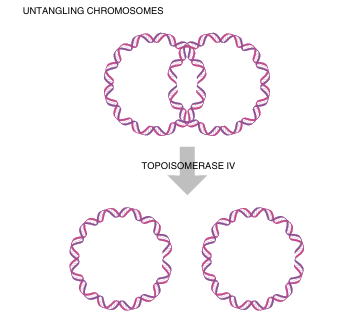
FIGURE 4.4 Untangling Circular Chromosomes
Sometimes after the replication of circular genomes is complete, the two rings are catenated, or linked together like links in a chain. Topoisomerase IV untangles the two chromosomes so they can partition into the daughter cells.
Priming DNA Synthesis
DNA polymerase cannot initiate new strands of nucleic acid synthesis because it can only add a nucleotide onto a pre-existing 3′-OH. Therefore, an 11 to 12 base-pair length of RNA (an RNA primer) is made at the beginning of each new strand of DNA. Since the leading strand is synthesized as a single piece, there is only one RNA primer at the origin. On the lagging strand, each Okazaki fragment begins with a single RNA primer. DNA poly merase then makes DNA starting from each RNA primer. At the origin, a protein called PriA displaces the SSB proteins so a special RNA polymerase, called primase (DnaG), can enter and synthesize short RNA primers using ribonucleotides. Two molecules of DNA polymerase III bind to the primers on the leading and lagging strands and synthesize new DNA from the 3′ hydroxyls (Fig. 4.5).
Primase, a special RNA polymerase, works with PriA to displace the SSB proteins and synthesize a short RNA primer at the origin. DNA polymerase then starts synthesis of the new DNA strand using the 3′-OH of the RNA primer. This synthesis occurs at multiple locations on the lagging strand
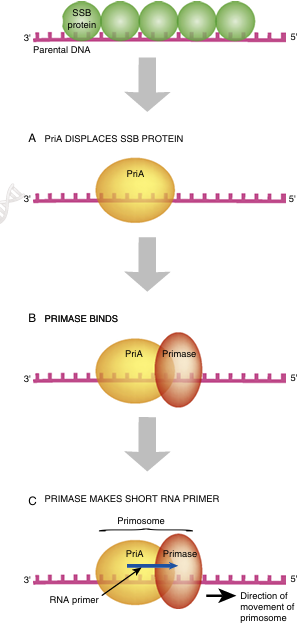
FIGURE 4.5 Strand Initiation Requires an RNA Primer
DNA polymerase cannot syn thesize new DNA without a pre-existing 3′-OH. Thus, DNA replication requires an RNA primer to initiate strand forma tion. (A) First, the PriA protein displaces the SSB proteins. (B) Second, primase associates with the PriA protein. (C) Last, the primase makes the short RNA primer.
Structure and Function of DNA Polymerase
DNA polymerase III (PolIII) is the major form of DNA polymerase used to replicate bacte rial chromosomes and consists of multiple protein subunits (see Fig. 4.2). The sliding clamp is a donut-shaped protein consisting of a dimer of DnaN proteins, also called the β-subunits. Two clamps encircle the two single strands of DNA at the replication fork. A cluster of acces sory proteins, called the clamp loader complex, loads the clamps onto DNA strands. The two sliding clamps bind two core enzymes, one for each strand of DNA. The core enzyme consists of three subunits: DnaE (α subunit), which links the nucleotides together; DnaQ (ε subunit), which proofreads the new strand; and HolE (θ subunit), which stabilizes the two other subunits (not shown in Fig. 4.2). As the α subunit adds new nucleotides, the ε sub unit recognizes any distortions and removes any mismatched bases. A correct nucleotide is then added. Bacterial DNA polymerase III can add up to 1000 bases per second, which is an extraordinarily fast rate of enzyme activity.
The multiple subunits of DNA polymerase III work together to synthesize a new strand of DNA. The core has two essential subunits: the α subunit links the nucleotides, and the ε subunit ensures that they are accurate.
Synthesizing the Lagging Strand
After the new lagging strand of DNA has been made, it has many segments of RNA derived from multiple RNA primers, as well as multiple breaks, or nicks, along the back bone that need to be sealed (Fig. 4.6). DNA polymerase I removes the RNA primers from the lagging strand. DNA polymerase I has exonuclease activity that removes the RNA bases, and then its polymerase activity fills in the regions with DNA bases. The RNA bases may also be removed by RNaseH, an enzyme that specifically identifies RNA:DNA hetero duplexes and removes the RNA bases. Finally, the DNA fragments of the lagging strand are linked together with a ligation reaction by DNA ligase. DNA polymerase I and DNA ligase are both very important enzymes in molecular biology and are used extensively in biotechnology.
Because the lagging strand is synthesized in small pieces, either DNA polymerase I or RNaseH excise the RNA bases and replace them with DNA. DNA ligase closes the nicks in the sugar/phosphate backbone of the new DNA strand.
Repairing Mistakes after Replication
After replication is complete, the mismatch repair system corrects mistakes made by DNA polymerase. If the wrong base is inserted and DNA polymerase does not correct the error itself, there will be a small bulge in the helix at that location. Identifying which of the two bases is correct is critical. The cell assumes that the base on the new strand is wrong and the original parental base is correct. The mismatch repair system of E. coli (MutSHL) deciphers which strand is the original by monitoring methylation. Imme diately after replication, the DNA is hemimethylated; that is, the old strand still has methyl groups attached to various bases, but the new strand has not been methylated yet (see Fig. 4.3). Two different E. coli enzymes add methyl groups: DNA adenine methylase (Dam) adds a methyl group to the adenine in GATC, and DNA cytosine methylase (Dcm) adds a methyl group to the cytosine in CCAGG or CCTGG. These enzymes meth ylate the new strand after replication, but they are slow. This allows mismatch repair to f ind and fix any mistakes first. Three genes of E. coli are responsible for mismatch repair: mutS, mutL, and mutH (Fig. 4.7). MutS protein recognizes the bulge or distortion in the sequence. MutH finds the nearest GATC site and nicks the nonmethylated strand—that is, the newly made strand. MutL holds the MutS plus mismatch and the MutH plus GATC site together (these may be far apart on the DNA helix). Finally, the DNA on the new strand is degraded and replaced with the correct sequence by DNA polymerase III.
In E. coli, mismatch repair proteins (MutSHL) identify a mistake in replication, excise the new nucleotides around the mistake, and recruit DNA polymerase III to the single-stranded region to make the new strand without a mistake.